Prompts#
The Prompt Runner is a powerful and versatile tool designed to streamline and enhance the process of interacting with multiple Language Models (LLMs). This tool empowers users to effortlessly run prompts against a variety of pre-trained LLMs and access a wealth of insights, responses, and solutions.
Sample prompting with Imprompt#
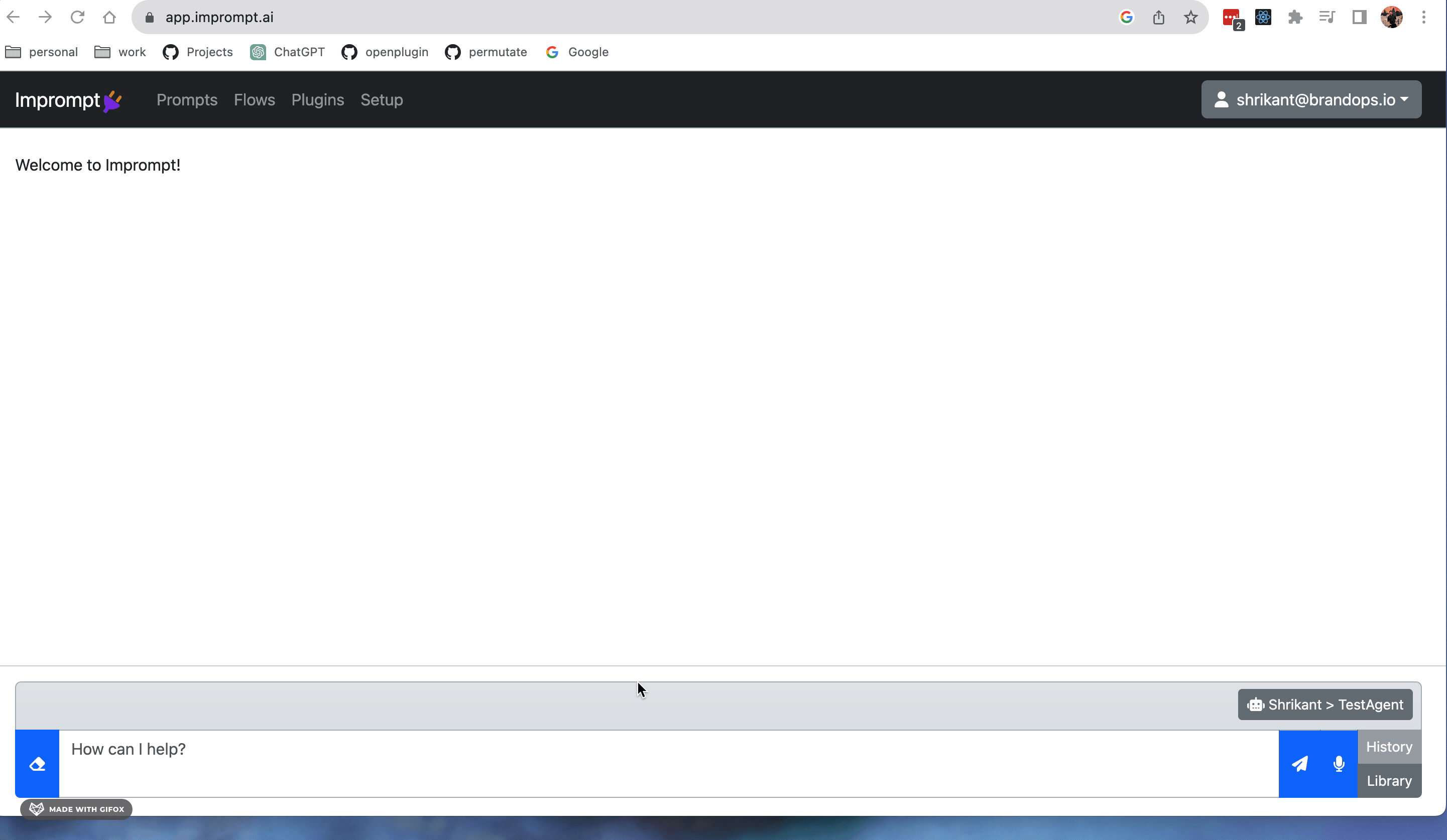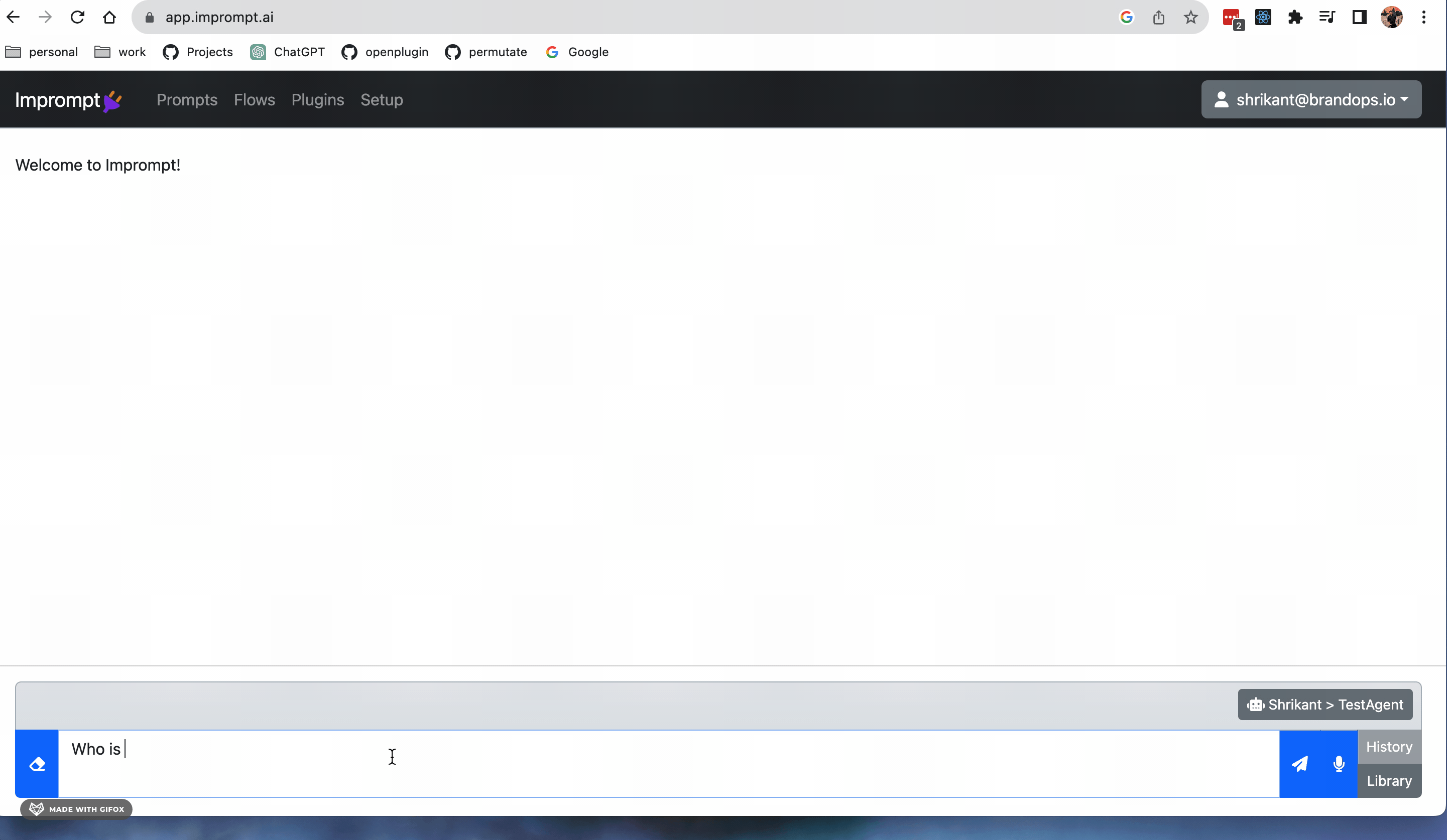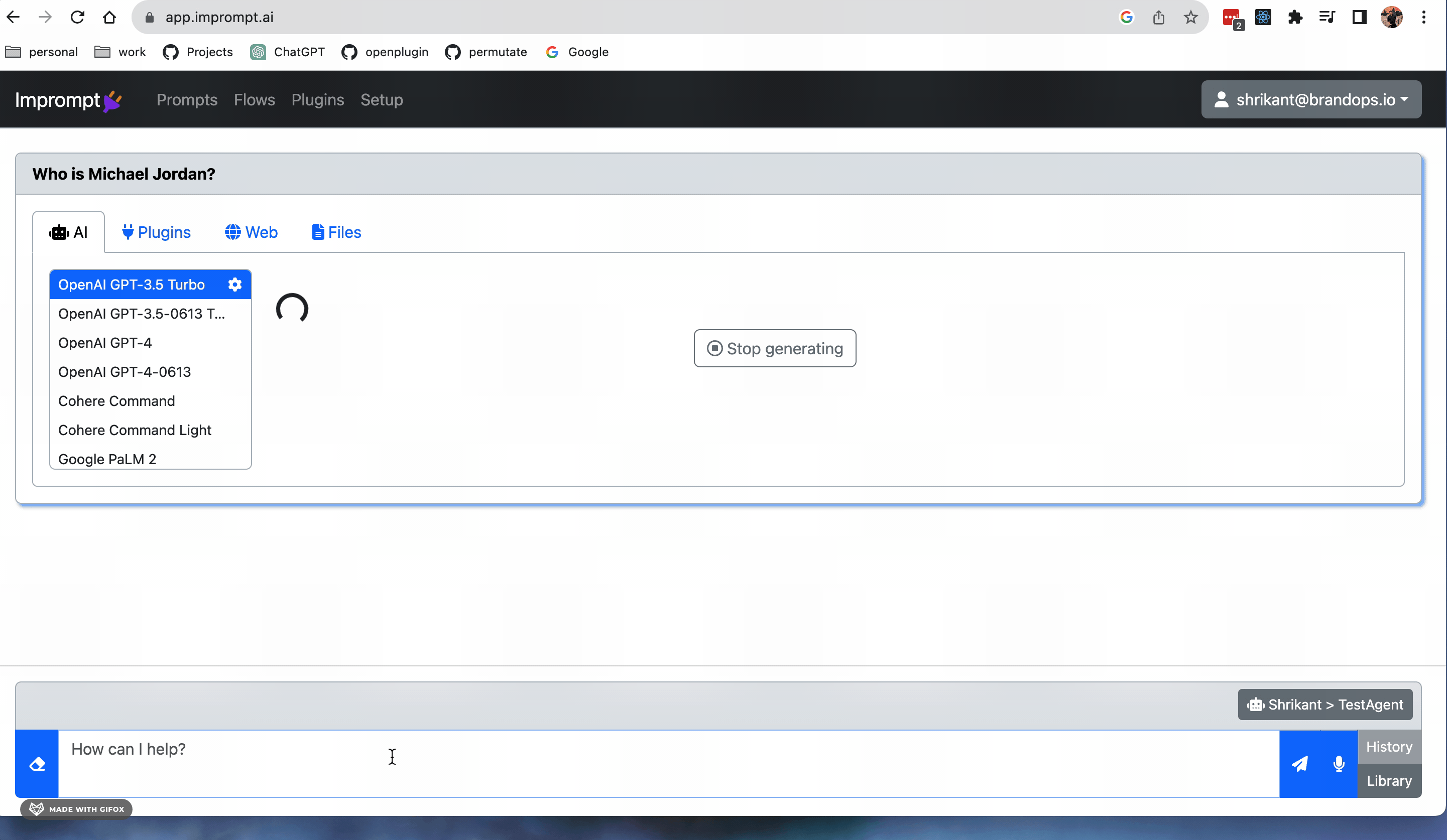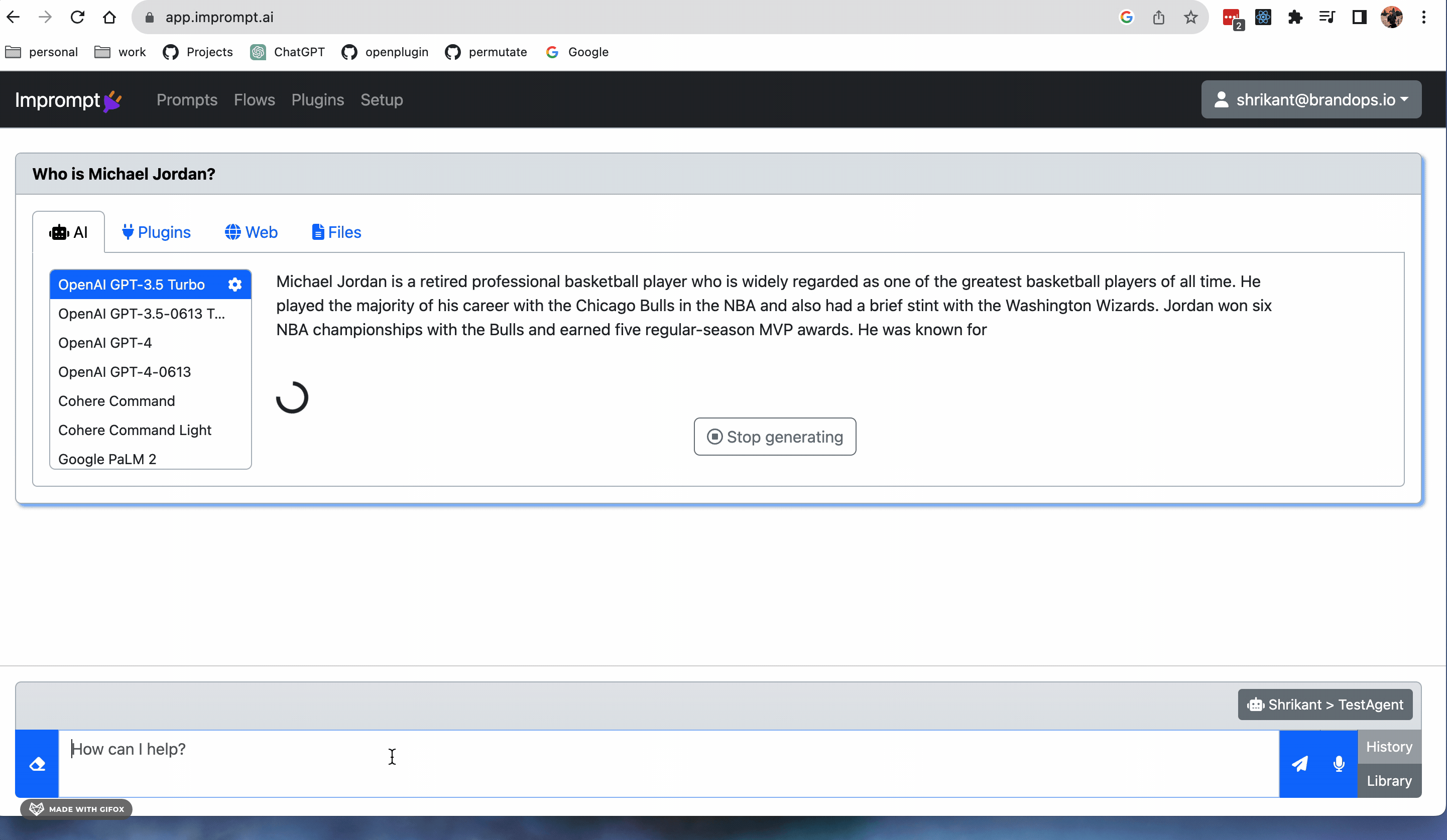
Supported LLM Models#
Model |
Max Tokens |
Description |
|---|---|---|
OpenAI GPT-3.5 Turbo |
4096 |
Most capable GPT-3.5 model and optimized for chat at 1/10th the cost of text-davinci-003. Will be updated with our latest model iteration 2 weeks after it is released. |
OpenAI GPT-3.5-0613 Turbo |
4096 |
Snapshot of gpt-3.5-turbo from June 13th 2023 with function calling data. Unlike gpt-3.5-turbo, this model will not receive updates, and will be deprecated 3 months after a new version is released. |
OpenAI GPT-4 |
8192 |
More capable than any GPT-3.5 model, able to do more complex tasks, and optimized for chat. Will be updated with our latest model iteration 2 weeks after it is released. |
OpenAI GPT-4-0613 |
8192 |
Snapshot of gpt-4 from June 13th 2023 with function calling data. Unlike gpt-4, this model will not receive updates, and will be deprecated 3 months after a new version is released. |
Cohere Command |
0 |
The priority ranking of the plugin in the catalog. The lower the number, the higher the priority. If not provided, the plugin will be added to the end of the catalog. |
Cohere Command Light |
0 |
The priority ranking of the plugin in the catalog. The lower the number, the higher the priority. If not provided, the plugin will be added to the end of the catalog. |
Google Palm2 |
0 |
The priority ranking of the plugin in the catalog. The lower the number, the higher the priority. If not provided, the plugin will be added to the end of the catalog. |
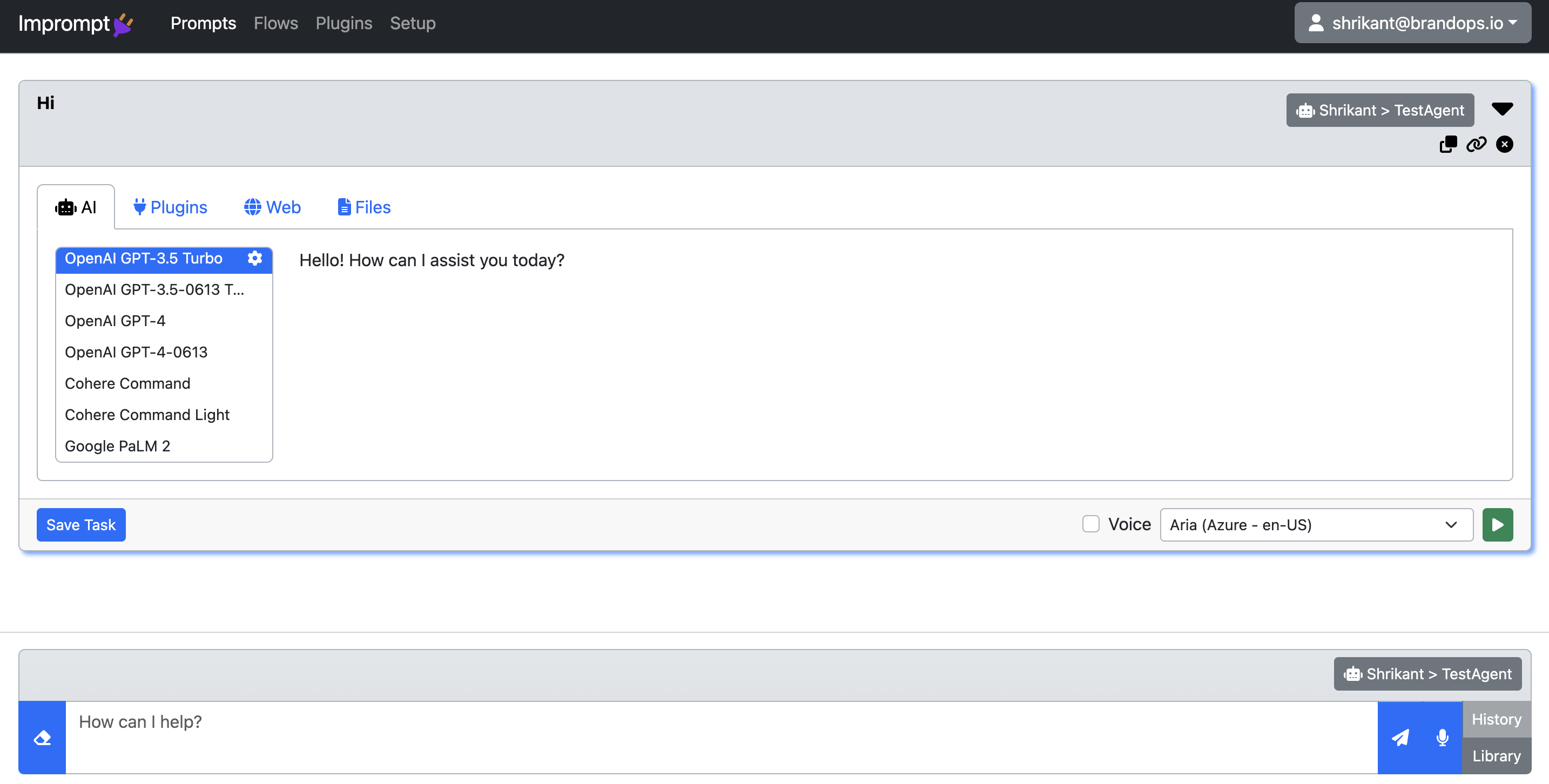
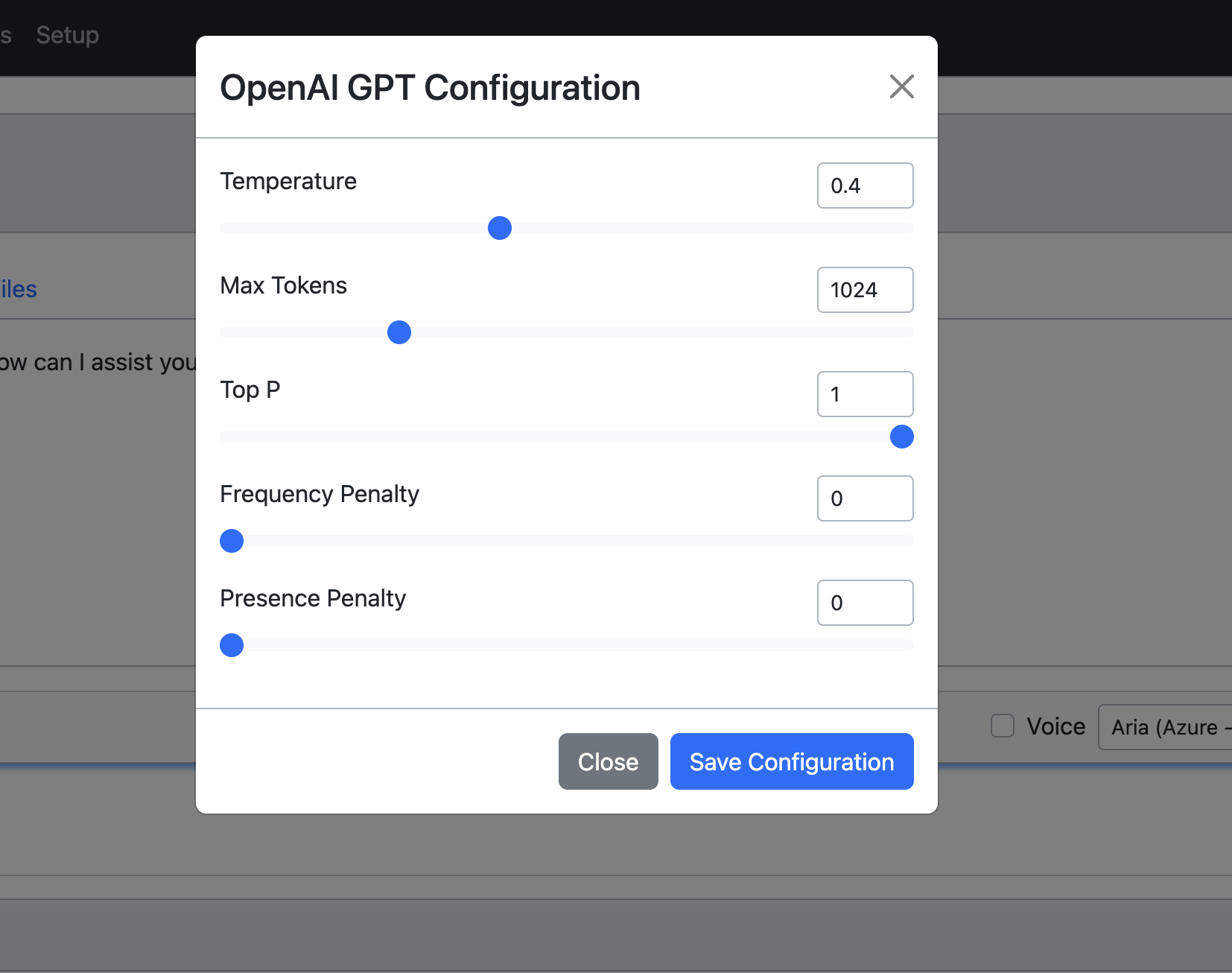
Supported LLM Configuration#
Field |
Default |
Description |
|---|---|---|
Temperature |
0 |
What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. |
Max Tokens |
1024 |
The maximum number of tokens to generate. |
Top P |
1 |
An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. |
Frequency Penalty |
0 |
Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim. |
Presence Penalty |
0 |
Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics. |